
Precision Bridge is a trusted partner in IT service management (ITSM), and in our years of operation, we’ve refined our solutions for data migration, archiving, replication and synchronization. One question we sometimes receive is “What about backups?”. This isn’t surprising, as backups are a bit easier to understand than data replication for those outside the IT world.
In this article, we'll explore both the similarities and the differences between data replication and backup and how both can benefit your business.
Comparing Data Back Ups, Replication, and Archiving
“Whilst data replication and data back up sound different, they’re actually similar”
Whilst data replication and data backup sound different, they’re actually similar in application. In fact, data backup is just one particular use case within the larger data replication umbrella. Let’s review each to make sure we’re all on the same page:
Data backup: A process that creates a secondary copy of data for the purpose of recovery in case of data loss, corruption, or system failures.
Data replication: Replication involves creating and maintaining multiple copies of data across different locations or systems, enabling quick access to data in case of system failures or disasters.
Data archiving: The purpose of data archiving is to preserve data for long-term retention, compliance, or historical reference. Archived data is typically less frequently accessed and may be retained for regulatory or legal requirements, business analysis, or other specific purposes.
With both data replication and backups, you copy data from one location to another without deleting the source data. This is a key distinction from archiving, which involves moving source data to storage systems designed for long-term preservation.
Both backups and replication can be run in real-time or on a scheduled basis, and both can involve replicating data between different servers, storage devices, or even geographic locations.
Data Recovery Options: Which Should I Use?

Although data backups are one of the most prevalent use cases for data replication, the motivations for choosing each these data management activities are quite different. In other words, why would a company choose to perform replication over a standard backup?
Data backups are specifically focused on creating a copy of data for disaster recovery and data loss situations. These could be the result of a natural disaster, human error, or a cybersecurity incident such as a ransomware attack. Should an event occur, the data backup reaches out to an external database to restore the data to its original system. Sometimes, the backup will be at the system level (e.g. a backup of everything including the hardware, software, application, and data) to create a full standby system.
Test your backups before disaster strikes – by then it’s too late!
Let’s compare this with data replication and its benefits, the first of which is performance.
System performance can be significantly affected by high levels of data access that may be required when companies run large or frequent reports. By replicating data to storage where it can be accessed independently, users reduce the workload on the application and improve performance overall.
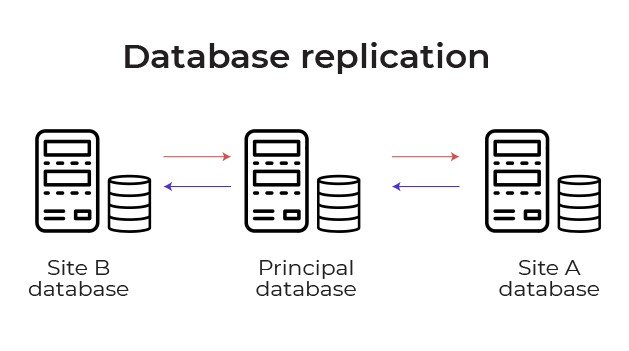
Another benefit has to do with reporting and analytics. Reporting can be improved across business locations by replicating the data into a centralized store, such as a data warehouse or data lake. This allows all reporting to be run from a single location and can greatly improve efficiency compared with conventional reporting processes.
Finally, though no less important, is how data replication cuts costs. Many systems charge per user, and strategic replication helps companies disperse data to relevant staff and reduce the number of licenses required.
Final Considerations for Data Management
Keep in mind that there are other important factors to consider when deploying a disaster recovery strategy. These include selecting the frequency of backups or replications, ensuring data integrity, handling complex data objects, and managing incremental updates.
The good news is that all of these can be handled with the right solution. At Precision Bridge, we’ve spent years designing a proprietary solution that takes care of all aspects of this process, allowing for simple configuration, automation, and validation to ensure it is straightforward and fast to set up data replication and archiving. Visit our site to learn more and prepare for your next migration project.
About the Author
Mark Herring is a co-founder of Precision Bridge and has been working in the ITSM space for nearly 30 years. Mark co-founded Precision Bridge in 2015 to address the market need for ITSM cross-platform migrations and has been involved in over 100 migration, replication, archiving, and data synchronization projects across a diverse range of ITSM platforms.